
Project Lineup













Illustration by Aquiboni

TIGER is an energetic, happy-go-lucky 20-something year old tiger-man. He's constantly lost in his head, thinking about what songs he's going to skate to at his roller-rink and what games he's gonna play on his Sega Dreamcast. He has a little buddy named 'Tigrito', who is a virtual pet that can pop out of his Tamagotchi-like device!TIGER was designed by the amazing Static and his official images were illustrated by the astounding Aquiboni.TIGER is a DiffSinger vocalist. While most of his data is recorded in English, he has support for Japanese and phonemes outside of English like Spanish and Portuguese! To learn more about using him, please read this page.Character Information:
Age: 25-29 | Height: 5'7 (5'9 on skates) | Weight: ~250lbs | Nationality: American | Occupation: Performer/Roller Rink OwnerVoice Information:
Provider: tigermeat | Data: ~2.5hrs | Languages: EN, ES, FR, JP, ZH
To download TIGER, click the button above that says "DOWNLOAD". If you need some pointers for installing, check out the usage guide by clicking the button above that says "USAGE GUIDE".
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!

MMD MODEL
Thanks to the amazing AlexFloareaVT, TIGER now has an MMD Model! Please see the demonstration below!!
Voice Samples
TIGER © 2021-2024 tigermeatCredits:
- TIGER Voice Provider: tigermeat
- TIGER Design: tigermeat & StaticOceans
- TIGER Original Standing Art: Aquiboni
- TIGER Recording, Development, Labels & Maintenance: tigermeat
- Microphones Used: Neumann TLM 103, AT4040, Rode NT1 Signature
- TIGER Logo: tigermeat
- TIGER MMD Model: AlexFloareaVTTGM databases are trained with "Millefeuille" to provide support for French.


Illustration by JulieRaptor

TRITON is a fun, somewhat aloof 20-something year old human & mermaid hybrid. He spends his days tending to his manatee farm off of the coast of the beach him and his partner TIGER live on. His right hand man is a rowdy manatee named Sheriff Spaghetti, and the two love tending the manatee farm together!TRITON was designed by the amazing Static & tigermeat, and his official images were illustrated by the amazing JulieRaptorTRITON is a DiffSinger vocalist. TRITON is recorded in English only, but by utilizing the Cross-Language compatibility of the TGM Dataset, he can sing in many different languages! You can utilize TRITON in OpenUTAU for Lunai. To learn more about using him, please read this page.Character Information:
Age: 25-29 | Height: 5'6 | Weight: ~230lbs | Nationality: American Merman | Occupation: Manatee FarmerVoice Information:
Provider: Ryan M. | Data: ~1hr | Languages: EN Only
To download TRITON, click the button above that says "DOWNLOAD". If you need some pointers for installing, check out the usage guide by clicking the button above that says "USAGE GUIDE".
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Samples
TRITON © 2021-2024 tigermeatCredits:
- TRITON Voice Provider: Ryan M.
- TRITON Design: tigermeat & StaticOceans
- TRITON Original Standing Art: JulieRaptor
- TRITON Recording, Development, Management, Labels & Maintenance: tigermeat
- Microphones Used: AT4040
- TRITON Logo: tigermeatTGM databases are trained with "Millefeuille" to provide support for French.


Illustration by Angela M. Chong.

Many years ago on a fateful day, Canary randomly arrived on Earth. He spends his days hanging out with robots and his boyfriend who happens to be a zombie.Canary is a DiffSinger vocalist. While most of his data is recorded in English, he has can sing in Japanese and Spanish as well! You can utilize Canary in OpenUTAU for Lunai. To learn more about using him, please read this page.Character Information:
Age: At least 200 (appears 20) | Height: 5'8 | Weight: Varies | Nationality: Space AlienVoice Information:
Provider: Mina Moonrise | Data: ~1.5hrs | Languages: EN, ES, JP, ZH
Canary is a member of the JAE VOCAL PROJECT, and was developed in collaboration with them and Mina Moonrise. Please click the "JAE PAGE" button above to visit their website and learn more about their projects and even more about Canary!To download Canary, click the button above that says "DOWNLOAD". If you need some pointers for installing, check out the usage guide by clicking the button above that says "USAGE GUIDE".
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Samples
Canary © 2019-2024 Mina Moonrise, JAE VOCAL PROJECT
Canary DS © 2023-2024 Mina Moonrise, tigermeatCredits:
- Canary Voice Provider: Mina Moonrise
- Canary Design: Mina Moonrise & Crusher
- Canary Key Standing Art: Angela M. Chong
- Canary Recording: Mina Moonrise
- Canary for DiffSinger Management, Development, Labels & Maintenance: tigermeat
- Microphones Used: AT2020
- Canary Logo: tigermeatTGM databases are trained with "Millefeuille" to provide support for French.


Illustration by Guillotama.

DANROU [d aa n r ow] is an UTAU character from 2013-2015 created by giraffeyyyy, aka tigermeat. DANROU is a young, excitable dragon learning how to navigate the world. He can be a bit reckless, but he's always has a pure heart.DANROU is now a DiffSinger vocalist. His voice was recorded between 2013 and 2015 for UTAU, now ported to DiffSinger. You can utilize DANROU in OpenUTAU for Lunai. To learn more about using him, please read this page.Character Information:
Age: 10 | Height: 4"3' | Weight: 120lbs | Nationality: Fluffy DragonVoice Information:
Provider: tigermeat | Data: 23 mins | Languages: JA
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Mode - Standard
Standard is based on DANROU's original VCV UTAU voicebank. It has a punchy tone with a cute twang.Best Genre's: Many, including Pop, Electronic, VOCALOID & more!
Voice Mode - Soft
Soft is based on DANROU's original Soft VCV UTAU voicebank. It has a airy, sweet tone and pairs well with Standard.Best Genre's: Many, including Pop, Ballads, VOCALOID & more!
Voice Mode - Light
Light is based on an unreleased 2-pitch CV UTAU voicebank for DANROU. It has a young and bright tone.Best Genre's: Many, including Pico-Pop, Electronic, VOCALOID & more!
XLS - Cross Language Synthesis
DANROU is a Japanese voice library for DiffSinger, but supports extra phonemes for other languages! Samples are coming soon.
DANROU © 2013-2024 tigermeat
DANROU DS © 2024 tigermeatCredits:
- DANROU Voice Provider: tigermeat
- DANROU Design: tigermeat & Guillotama
- DANROU Recording: tigermeat
- DANROU for DiffSinger Management, Development, Labels & Maintenance: tigermeat
- Microphones Used: Blue Yeti
- DANROU Logo: tigermeatTGM databases are trained with "Millefeuille" to provide support for French.


Illustration by ひやま

Miyo is a nonbinary rabbit yao who strives to be the best helper in the world! They are extremely benevolent and selfless to the point of hardly ever taking time for themselves, even if risking burnout.Miyo is a DiffSinger vocalist. Miyo was recorded to sing in English, Japanese and Chinese, but can sing in many languages with XLS! You can utilize Miyo in OpenUTAU for Lunai.Character Information:
Age: Unknown (Appears 24) | Height: 5'5" | Weight: Secret | Species: Rabbit YaoVoice Information:
Provider: 実偽Migi | Data: ~90min | Languages: EN, JA, ZH
To download Miyo, click the button above that says "DOWNLOAD". If you need some pointers for installing, check out the usage guide by clicking the button above that says "USAGE GUIDE".
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Samples
Miyo © 2023-2024 実偽Migi
Miyo for DiffSinger © 2024 tigermeat, 実偽MigiCredits:
- Miyo Voice Provider: 実偽Migi
- Miyo Design: TSaianda (maid, butler), Fiorrie (traditional)
- Miyo Key Standing Art: ひやま
- Miyo Recording: 実偽Migi
- Miyo for DiffSinger Management, Development & Maintenance: tigermeat
- Miyo for DiffSinger Labels: tigermeat & FerretFather
- Microphones Used: AT2020
- Miyo Logo: リノTGM databases are trained with "Millefeuille" to provide support for French.

A crude and abrasive young girl. Bitter sings in a deep, harsh but energetic and chaotic style.She is the best friend of Sweet, older sister of Sour, and one half of the BitterSweet duo. Her knife is named 'Mrs. Butterfingers', which she treats like a living friend.Bitter is a DiffSinger vocalist. Bitter was recorded to sing in English and Japanese, but can sing in many languages with XLS! You can utilize Bitter in OpenUTAU for Lunai.Character Information:
Age: 20 | Height: 5'3" | Birthday: February 8thVoice Information:
Provider: Guillotama | Data: ~35min | Languages: EN, JA

Illustration by Guillotama
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Samples
Bitter © 2021-2026 Tasteloid, Guillotama
Bitter for DiffSinger © 2026 tigermeat, Tasteloid, GuillotamaCredits:
- Bitter Voice Provider: Guillotama
- Bitter Design: Guillotama
- Bitter Key Standing Art: Guillotama
- Bitter Recording: Guillotama
- Bitter for DiffSinger Management, Development & Maintenance: tigermeat
- Bitter for DiffSinger Labels: tigermeat & Guillotama
- Microphones Used: TBATGM databases are trained with "Millefeuille" to provide support for French.


Illustration by Guillotama
A gentle and caring big sister type. Sweet's voice ranges from smooth bass to fluttering highs.She is the best friend of Bitter, and one half of the BitterSweet duo. She carries an oversized spoon called 'Dipper' and likes to bake treats for Sour.Sweet is a DiffSinger vocalist. Sweet was recorded to sing in English and Japanese, but can sing in many languages with XLS! You can utilize Sweet in OpenUTAU for Lunai.Character Information:
Age: 23 | Height: 5'8" | Birthday: March 5thVoice Information:
Provider: Guillotama | Data: ~30min | Languages: EN, JA
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Samples
Sweet © 2021-2026 Tasteloid, Guillotama
Sweet for DiffSinger © 2026 tigermeat, Tasteloid, GuillotamaCredits:
- Sweet Voice Provider: Spectrabund
- Sweet Design: Guillotama
- Sweet Key Standing Art: Guillotama
- Sweet Recording: Guillotama
- Sweet for DiffSinger Management, Development & Maintenance: tigermeat
- Sweet for DiffSinger Labels: tigermeat
- Microphones Used: AT2020TGM databases are trained with "Millefeuille" to provide support for French.


Illustration by missile39

Adachi Rei (足立レイ) is a character & voice created by missile39. Her voice was artificially created in Audacity by manipulating the formants of generated audio to create artificial vocal sounds.With permission from her creator, missile39, I was able to edit & manipulate her audio samples and train them as a DiffSinger library! By utilizing her DiffSinger library, Adachi Rei can sing in 12 languages, and is easier to use than ever before! Unlike other variations of her voice made to sing in languages other than Japanese, the audio used to create Adachi Rei for DiffSinger comes entirely from her UTAU version 3.1.2, and not from AI voice changers. Doing it this way, we get the most accurate and realistic (if you want to call it that) representation of Rei's voice in languages other than Japanese.To read more about Rei, please visit her official website here!
To download Adachi Rei, click the button above that says "DOWNLOAD". If you need some pointers for installing, check out the usage guide by clicking the button above that says "USAGE GUIDE".
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Voice Samples
足立レイ © 2017-2025 missile39, Mechanical Girl LLC
足立レイ for DiffSinger © 2025 tigermeatCredits:
- 足立レイ Creator: missile39
- 足立レイ for DiffSinger Management, Development & Maintenance: tigermeatTGM databases are trained with "Millefeuille" to provide support for French.


Illustration by FerretFather

Leif was created in collaboration with FerretFather and tigermeat. He is recorded in English and Japanese, and comes with 4 voice modes: Blossom, Petal, Uprooted and Lush. They are split into 8 different modes however, each voice mode has an English and Japanese version.Description from FerretFather: "Being quite literally nothing but a mass of plants, be can seem quite aloof or unfocused. His behavior, while vaguely human, can seem awkward and unusual. He does go out of his way however to display acts of kindness and cares deeply for those in close proximity to him. Depending on his perceived mood, he can sprout different colors of flowers in his beard. Being comprised of nothing but plants, Leif technically does not have a gender, but uses he/they pronouns and seems to be attracted to men."
Please take a listen to this demonstration of Leif's Voice!
OpenUTAU for Lunai
I recommend using all TGM DiffSinger libraries with "OpenUTAU for Lunai", a fork of OpenUTAU made specifically for DiffSinger. You can download it at the link below! You can read more on Lunai Project's Website!
Leif © FerretFatherLeif's voice and image is intellectual property of FerretFather.

LabelMakr is a GUI tool to assist you in creating phoneme-level transcriptions for sung audio data. LabelMakr utilizes Whisper by OpenAI and SOFA by qiuqiao to automatically transcribe and force-align at a word and phoneme level! LabelMakr has a built in transcription editor so you can make sure the generated transcriptions are accurate!To use LabelMakr, click "download" above to download the portable Windows version, or download the source code from the "Github" link above!
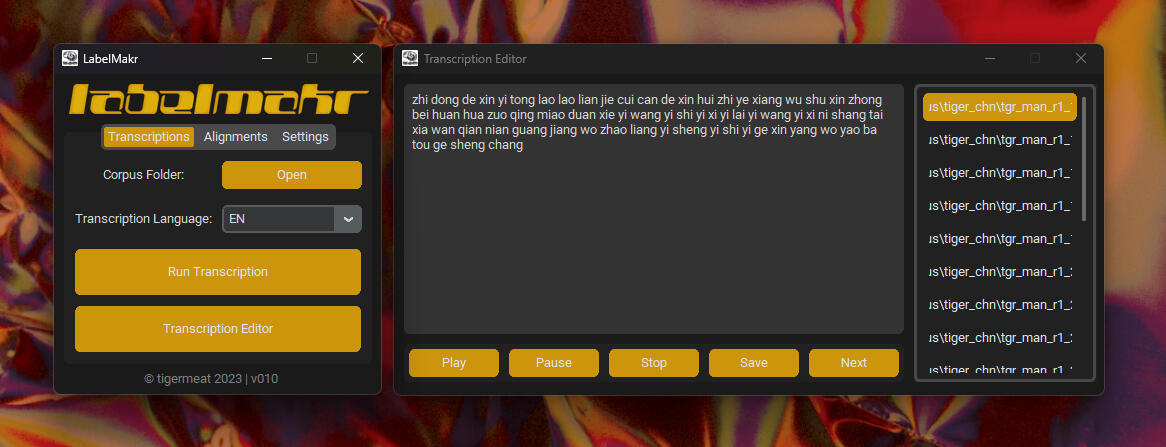
A screenshot of LabelMakr and the built in transcription editor.

I have moved my sequence file repository to the new website vocaloader.app! Check out my Sequence Files there, and join in if you'd like! The following rules are still required to be followed when using my Sequence Files.
You will provide credit to me (tigermeat) and any other parties listed in the "readme" file of the specific file. Likewise, you will not claim that you created them.
You will NOT redistribute edits/other formats of my files. No exceptions.
You MAY tune, edit, or change any part of the files, so long as it can not be construed as offensive or targeted (ex: Offensive parody version of a song, etc.)
'tigermeat character' Terms of Use
Usage of all TGM Characters image, name and voice models of any kind fall under a CC BY-NC-ND 4.0 & Commons Clause License. This page will further explain the license, as well as introduce terms and conditions for usage of a tigermeat character's name/image. Any questions or concerns can be brought to me directly by emailing me at [email protected].
Section 1: Standard Usage
Upon downloading any image or voice model of a TGM Character, you agree to all terms written on this page, as well as outlined in the CC BY-NC-ND 4.0 & Commons Clause License.
Any use of a TGM character cannot under ANY circumstance promote hate, racism, homophobia, sexism, transphobia, misogyny, or any type of negativity towards a group of people with intentions to harm.
TGM Characters may not be used to portray any illegal activity under United States law, and the law of the country the TGM Character is being used in.
TGM Characters shall not be portrayed as any race other than the race they appear to be in official illustrations & especially character reference sheets. Please do not change the complexion of the character drastically. Lighting changes are fine, but please be respectful of the characters race.
R18, NSFW or Explicit work is acceptable for the following TGM Characters: TIGER, TRITON. You may use these characters names, images or voice models in NSFW works so long as the actions portrayed in said content is legal under the laws of the United States of America AND the home country of the user, if they are not residing in the United States of America. If you are unsure if your work is allowed because of NSFW content, please contact tigermeat.
Please do not use TGM Characters to spread harmful misinformation, such as uninformed or bias news and science.
You ABSOLUTELY MAY use TGM Characters to do any of the following: Spread love, speak on social issues so long as they do not spread or condone hate to any group, inform others on events, and much more!
Section 2: Code Usage
As is the nature of user-focused voice AI, there is some code involved. Please follow all rules outlined in the CC BY-NC-ND 4.0 & Commons Clause License when utilizing TGM Character voice models for any purpose.
TGM Character voice models can be used as a warm start for training other models, if applicable to the type of voice model (Not available for DiffSinger due to models being exported to ONNX for use in OpenUTAU) so long as proper attribution under CC BY-NC-ND 4.0 is provided.
You may not use ANY TGM models for data distillation, reverse engineering or AI Training in any way.
Section 3: Commercial Use
Commercial usage of TGM Characters is acceptable so long as a license is purchased from tigermeat. To acquire the license, click the "Commercial License" button on each respective character's page. You can purchase the license as a digital-only delivery item, or purchase the physical version of a voice if it exists.Commercial usage of TGM DiffSinger models is currently not allowed, but there are plans to change this. If you already own a Commercial License of a TGM character, you retain rights to utilize the characters name, likeness and visuals in a commercial application, but not their DiffSinger model.
The usage of all TGM Characters names, images, and voice models in any type of Crypto Currency or NFT work is STRICTLY PROHIBITED and will not be tolerated under ANY circumstances.
TGM Character license fees for commercial use falls under any usage that would generate revenue for or by any means. This includes charity, however TGM Character licensing fees may be discounted/waved for charities or carity events. Please email tigermeat to find out more if you're interested!
Section 4: Visual Usage
In using TGM Character images, you agree to publicly state the name of the illustrator of said image. Any official image of TGM Characters will clearly state the illustrator either in supporting documents or the file name.
In using TIGER's official illustrations by Aquiboni, you must state they were illustrated by Aquiboni in the published work with no exceptions. The illustrations cannot be edited or changed significantly or stated/implied to be a separate character. (EX: fan-made derivative)
The usage of any of TGM Character's visuals for use in generative image AI model training is STRICTLY PROHIBITED and will not be tolerated under ANY circumstances.
'Canary' Terms of Use
This section is pulled directly from Canary's page on the JAE website. For the most current information, please check out this page.
Section 1: General Terms
Do not claim Canary or official artwork as your own.
NSFW content is allowed. This does not apply to MMD models and other works from people who are not from the JAE VOCAL PROJECT group. Please follow the rules of the creators! If their works are not allowed to be used for NSFW content, then do not use them for NSFW content!
For commercial use of his voicebanks and character, permission is required.
Commercial use of his DiffSinger library is prohibited currently.
Derivatives must be made with permission.
Oto.ini editing is allowed.
Do not edit Canary's samples.
Shippings and pairings are allowed, but do not force as canon. Do not ship Canary with characters under the age of 18.
Do not use Canary's character and voicebanks for hate speech.
Political use is not allowed.
Voicebank redistribution is forbidden.
Unofficial roleplay, accounts, and ask blogs are allowed if permission from Mina Moonrise is given. Must credit JAE VOCAL PROJECT and Mina Moonrise for character rights. Must credit the appropriate artists if using official. Do not use art from non-members without their permission. Cannot violate existing ToS (no shipping with minors, hate speech, etc). For any questions, please contact JAE VOCAL PROJECT or Mina Moonrise.
Regarding AI creations: Creating the character of Canary through AI artwork generation applications and software is prohibited. Using artwork of Canary to train AI artwork generation applications and software is prohibited, especially without the explicit consent of both JAE VOCAL PROJECT and the original artist. Using Canary's UTAU and DeepVocal voicebanks to train and create, use, and distribute AI voices and voicechangers is prohibited without explicit consent of both JAE VOCAL PROJECT and Mina Moonrise.
Section 2: Code Usage (Specific to Canary DS Only)
As is the nature of user-focused voice AI, there is some code involved. Please follow all rules outlined in the CC BY-NC-ND 4.0 & Commons Clause License when utilizing TGM Character voice models for any purpose.
TGM Character voice models can be used as a warm start for training other models, if applicable to the type of voice model (Not available for DiffSinger due to models being exported to ONNX for use in OpenUTAU) so long as proper attribution under CC BY-NC-ND 4.0 is provided.
TGM Phoneme Guide
On this page, you'll find a guide for using the "TGM" Phonetic system. English phonemes are standard arpabet, but to provide support for other languages, there are some extra phonemes. I'll be providing equivalents to other DiffSinger standard systems, as well as their X-Sampa or V-Sampa equivalent. NOTE: V-Sampa is my shorthand for Vocaloid X-Sampa, since it differs from standard X-Sampa in some cases. The English X-Sampa examples include Standard X-Sampa, and V-Sampa where it differs from standard X-Sampa.NOTE: All fully supported languages, which are listed here, can be used without the need for manual phonetic editing by using the respective Phonemizer in OpenUTAU. This chart is purely for those interested in manually editing phonetics while using TGM voices.To learn more about X-Sampa, please check out the Wikipedia page here!
Base English Phonemes
| TGM | Arpabet | X-Sampa | TGM | Arpabet | X-Sampa | TGM | Arpabet | X-Sampa |
|---|---|---|---|---|---|---|---|---|
| aa | aa | a, Q | b | b | b, bh | s | s | s |
| ae | ae | { | ch | ch | tS | sh | sh | S |
| ah | ah | V | d | d | d, dh | t | t | t, th |
| ao | ao | O | dr | d r | dr\, dZr\ | th | th | T |
| aw | aw | aU, {U | dh | dh | D | tr | t r | tr\, tSr\ |
| ax | ax | @ | f | f | f | v | v | v |
| ay | ay | aI, AI | hh | hh | h, h\ | w | w | w |
| eh | eh | E | g | g | gh | y | y | j |
| er | er | @`, @r | jh | jh | dZ | z | z | z |
| ey | ey | eI | k | k | k, kh | zh | zh | Z |
| ih | ih | I | l | l | l, 5 | q | q, cl | ? |
| iy | iy | i, i: | m | m | m | dx | dx | 4 |
| ow | ow | @U, oU | n | n | n | |||
| oy | oy | OI, oI | ng | ng | N | |||
| uh | uh | U | p | p | p, ph | |||
| uw | uw | u, u: | r | r | r\ |
General "Special" Phonemes
| TGM | X-Sampa | Notes |
|---|---|---|
| SP | N/A | Silence |
| AP | N/A | Breath/Inhale |
| cl | _} | Diacritic for removing the "pop" from an ending plosive consonant. |
| vf | N/A | Vocal Fry |
| bk | N/A | Voice Break |
French Phonemes
The French system used in TGM is based on "Millefeuille." Read more about it on the Github repo here!
| TGM | MIL | X-Sampa | TGM | MIL | X-Sampa | TGM | MIL | X-Sampa |
|---|---|---|---|---|---|---|---|---|
| a | ah | a | b | b | b | z | z | z |
| ee | eh | e | d | d | d | zh | j | Z |
| eh | ae | E | f | f | f | y | y | j |
| ax | ee | @ | g | g | g | w | w | w |
| oe | oe | 2 | k | k | k | uy | uy | H |
| iy | ih | i | lg | l | l | |||
| oo | oh | o | m | m | m | |||
| oh | oo | O | n | n | n | |||
| uu | ou | u | p | p | p | |||
| yu | uh | y | rh | r | R | |||
| aan | en | A~ | s | s | s | |||
| ehn | in | E~ | sh | sh | S | |||
| yn | un | 2~ | t | t | t | |||
| on | on | o~ | v | v | v |
In TGM, the word "bonjour" would be b on zh uu rh, but in Millefeuille it would be b on j ou r.
Spanish Phonemes
The Spanish system in TGM is based off of the way Gianloop's TISD is labelled.
| ES | TGM | V-Sampa | ES | TGM | V-Sampa | ES | TGM | V-Sampa |
|---|---|---|---|---|---|---|---|---|
| padre | a | a | perro | px | p | tuyo | tx | t |
| enero | ee | e | quise | kx | k | bestia | b | b |
| mío | iy | i | obtuso | bv | B | dedo | d | d |
| foco | oo | o | dedo | dh | D | gato | g | g |
| musa | uu | u | trigo | gv | G | concha | ch | tS |
| ciudad | y | j | fase | f | f | cerro* | th | T |
| huevo | w | w | casa | s | s | México | hx | x |
| muy | y | I | sin | n | n | año | ny/n y | J |
| neutro | w | U | lana | lg | l | caro | rs | r |
| pollo | y | L/j\ | carro | rr | rr |
*: European Spanish
In TGM, the word "Perro Salchicha" would be [px ee rr oo] [s a lg ch iy ch a], but in V-Sampa it would be [p e rr o] [s a l tS i tS a].
Japanese Phonemes
The Japanese system in TGM is a custom triphonic system.
| TGM | V-Sampa | TGM | V-Sampa |
|---|---|---|---|
| a | a | n | n |
| iy | i | n y | J |
| ux | M | hh | h / h\ |
| ee | e | hh y | C |
| oo | o | fp | p\ |
| nn | N/N/N` | fp y | p' |
| kx | k | b | b |
| k y | k' | b y | b' |
| g | g | px | p |
| g y | g' | px y | p' |
| s | s | m | m |
| sh | S | my | m' |
| dz | z | y | j |
| tx | t | rj | 4 |
| tx y | t' | rj y | 4' |
| ts | ts | w | w |
| ch | tS | d | d |
| dz | dz | d y | d' |
| q | ? |
In TGM, the word "熱帯魚" would be n ee q tx a iy g y oo, but in V-Sampa it would be n e ? t a i g' o.
Mandarin Chinese Phonemes
The Mandarin Chinese system used in TGM is a custom triphonic System. This is different from the standard DiffSinger Chinese system, as sounds are broken into two OR three phonemes, instaed of just two.This system is imperfect, and is only meant to allow non-Mandarin speaking singers to sing in Mandarin.
| Pinyin | TGM | V-Sampa | Pinyin | TGM | V-Sampa | Pinyin | TGM | V-Sampa |
|---|---|---|---|---|---|---|---|---|
| a | a | a | iao | ia w | iAU | b- | b | p |
| o | oo | o | iu | io w | i@U | p- | p | p_h |
| e | ex | 7 | an | a xn | a_n | m- | m | m |
| i | iu | i | en | ex xn | @_n | f- | f | f |
| u | uu | u | in | iy xn | i_n | d- | d | t |
| v/ü | yu | y | ian | ie xn | iE_n | t- | t | t_h |
| er | er | @` | uan | ua xn | ua_n | n- | n | n |
| ci/zi | iz | i\ | un | uex xn | u@_n | l- | l | l |
| shi | ir | i` | vn/ün | yu xn | y_n | g- | g | k |
| ai | ay | aI | van/üan | ye xn | y{_n | k- | k | k_h |
| ei | ey | ei | ang | aa ng | AN | h- | hx | x |
| ao | au | AU | eng | ex ng | @N | j- | jy | ts\ |
| ou | ow | @U | ing | iy ng | iN | q- | qy | ts_h |
| ia | ia | ia | iang | ia ng | iAN | x- | xy | s\ |
| ia(n) | ie | iE_r | uang | ua ng | uAN | zh- | jh | ts` |
| ua | ua | ua | ueng | uex ng | u@N | ch- | ch | ts`_h |
| uo | uo | uo | ong | oo ng | UN | sh- | sh | s` |
| ve/üe | ye | yE_r | iong | io ng | iUN | r- | rz | z` |
| uai | w ay | uaI | z- | dz | ts | s- | s | s |
| uei | w ey | uei | c- | ts | ts_h | -n | xn | _n |
In TGM, the sentence " 她在吃水果 (tā zài chī shuĭguŏ)" would be [t a] [dz ay] [ch ir] [sh w ey] [g uo].
Korean Phonemes
The Korean system used in TGM is based on the Korean phonetic system by "CODA-SVS" and the Korean support in the VB's mainly come from Kitane Sno's Korean DiffSinger DB. For more information, please check out this document!
| 한굴 | TGM | V-Sampa | 한굴 | TGM | V-Sampa | 한굴 | TGM | V-Sampa |
|---|---|---|---|---|---|---|---|---|
| 아 | a | a | ㄱ- | g | g | ㅊ- | ch | ch |
| 애/에 | ee | e | ㄲ- | kx | g' | ㅋ- | k | k |
| 이 | iy | i | ㄴ- | n | n | ㅌ- | t | t |
| 오 | oo | o | ㄷ- | d | d | ㅍ- | p | p |
| 우 | uu | u | ㄸ- | tx | d' | ㅎ- | hh | h |
| 어 | eo | 7 | ㄹ- | rj | r | -ㄱ | kq | gp |
| 으 | ux | M | -ㄹㄹ- | lx | l | -ㄴ | n | np |
| 야 | y a | ja | ㅁ- | m | m | -ㅅ | tq | dp |
| 얘/예 | y ee | je | ㅂ- | b | b | -ㄹ | rl | rp |
| 요 | y oo | jo | ㅃ- | px | b' | -ㅁ | m | mp |
| 유 | y uu | ju | ㅅ- | sx | s | -ㅂ | pq | bp |
| 여 | y eo | j7 | 샤 | shx | sh | -ㅇ | ng | Np |
| 와 | w a | oa | ㅆ- | s | ss | |||
| 왜 | w ee | ue | 쌰 | sh | sh' | |||
| 외 | w iy | ui | ㅈ- | c | c | |||
| 워 | w eo | u7 | ㅉ- | jh | c' |
In TGM, the word "한굴" would be hh a n g uu rl, but in V-Sampa it would be h a np g u rp.

icon by @bayboyzone
Well Hello There!
Howdy! I'm Tyler. I'm 25, from Chicago and do lots of internet things. I currently am focused hard on developing voices for DiffSinger, but I also code apps and things in Python! If you have a question, or just wanna say hi, feel free to hit me up at any of the places below! You'll see me the most active on twitter, however!
Contact me
DiffSinger Install/Usage Guide
In this guide, you'll find some information on how to install and utilize DiffSinger. The guides to install are specific to TGM Characters, but usage is pretty universal!All guides on this page will be using Windows 11, but the same steps should apply for your personal operating system. As always, if you have any questions, feel free to reach out to me directly!
Step 1: Download Voice + Install
First, you'll need to install OpenUTAU. TGM DiffSingers will work on any fork of OpenUTAU that supports DiffSinger, however I recommend using the main, official version of OpenUTAU. Please follow this link to download OpenUTAU from Github. The Github page has a few guides to ensure you're able to install properly!Next, you'll want to download the voice library. On each characters respective page, you'll want to click "Download", generally the first button at the top of their page. You'll download a file called something like "TIGER_DS_(version#)_PACK.zip". This will include all of the necessary things you need to use the voice.Upon unzipping the "pack" file, you'll see something similar to this screenshot below.
"Voice Library" contains the voice library. Drag the ".zip" file in that folder into OpenUTAU, hit "apply" on the prompt that pops up and once all of the items are unloaded, you'll be able to start using the voice!"OpenUTAU Plugins" contains any custom plugins the singer can use, specifically the TGM English Phonemizer. Drag the ".dll" files into OpenUTAU and click "okay" on the prompt for each. You'll need to restart OpenUTAU to use these phonemizers.

After completing the steps above, you're ready to start using DiffSinger in OpenUTAU!
Step 2: Adjust Settings in Preferences
By default, OpenUTAU will try to render DiffSinger with the default settings, which I highly recommend changing. To adjust, in the main window click "Tools > Preferences..."
Scroll down to "Rendering".If you do not have a GPU in your system, or are not using a Windows version of OpenUTAU, you'll want to leave "Machine Learning Runner" as the default. If you have a GPU on Windows, change it to "directml". If you are using a GPU, ensure the proper one is selected in the "GPU" drop-down box.Ensure "DiffSinger Render Depth" is set to 400, and you can change "DiffSinger Render Speedup" depending on your preference.For DDSP Models:
Higher Quality = Lower Numbers
Lower Quality = Higher Numbers
"Prefer Quality" = 1
"Prefer Speed" = 100For Reflow Models (TGM v106 and up):
Higher Quality = Higher Numbers
Lower Quality = Lower Numbers
"Prefer Quality" = 100
"Prefer Speed" = 1

Step 3: Basic Usage
For using a DiffSinger voice for the first time, you'll want to select the voice from the track and ensure you're using the proper phonemizer!

To select the singer, click on "Select Singer" from the track you're using. If you do not see a newly installed singer there, click on "DiffSinger..." at the bottom, and an expanded list of installed singers will appear for you to choose from.
To select the phonemizer, click the line below "Select Singer" after selecting a singer, and choose from a list of Phonemizers. All DiffSinger phonemizers have the prefix "DIFFS". DiffSinger will only work with the special DiffSinger phonemizers. TGM Voices work best with "DIFFS EN" or "DIFFS EN TGM", but all voices will support "DIFFS", "DIFFS ES", and the yet-to-be-released "DIFFS JA". To use voices in Japanese, currently support is available via "DIFFS" by using Hiragana lyrics.

Step 4: Editing the Voice
This section will cover utilizing DiffSinger in the most efficient way possible, like directly editing phonemes, using the built in pitch model, and putting the voice modes to work!

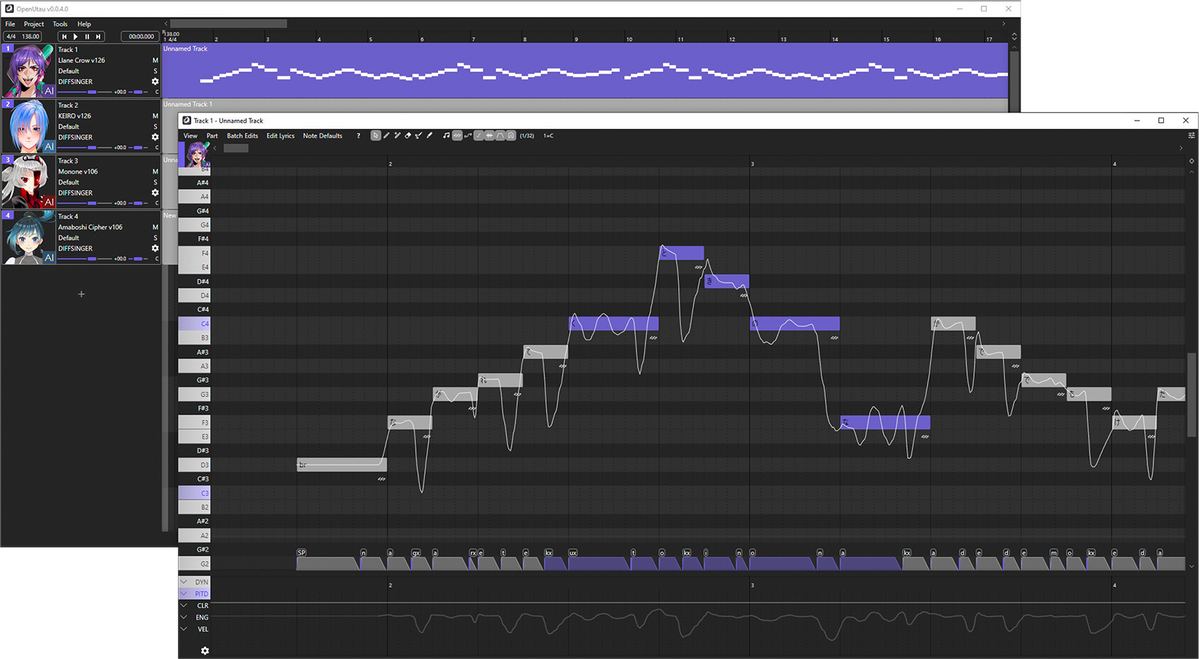
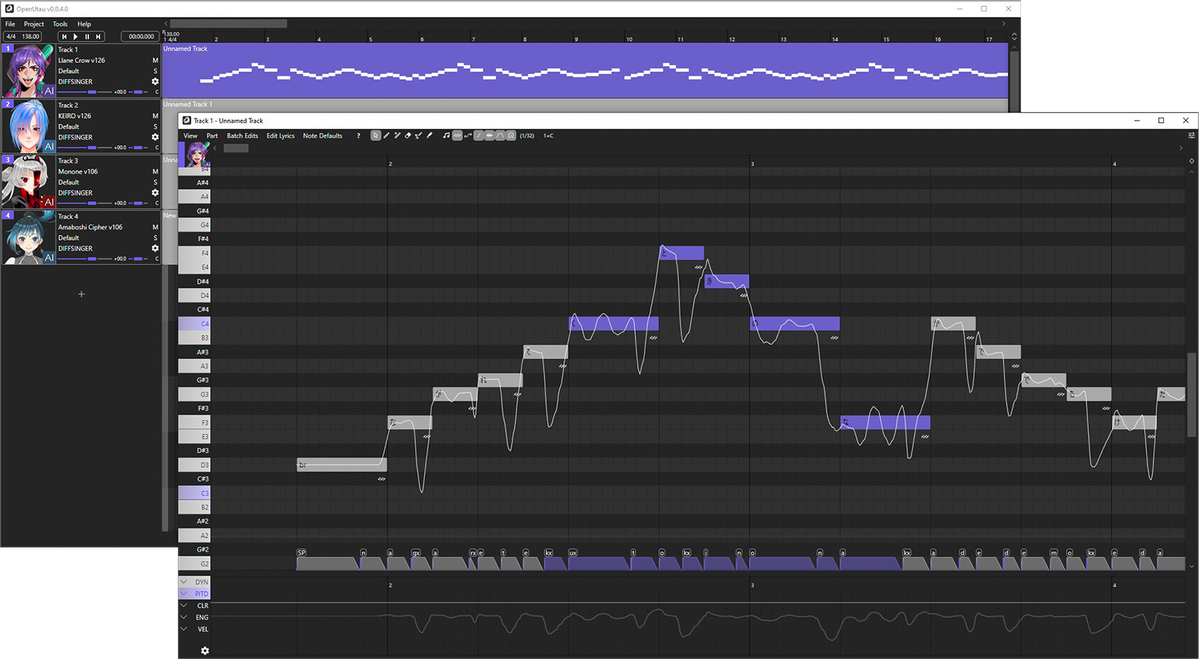
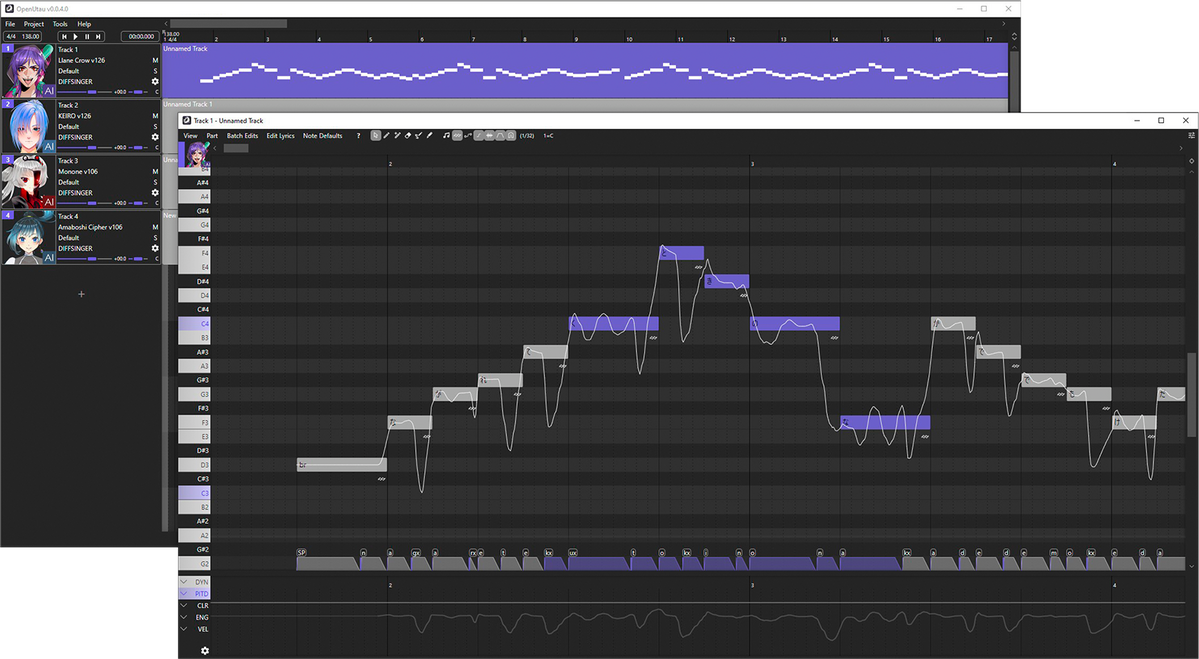
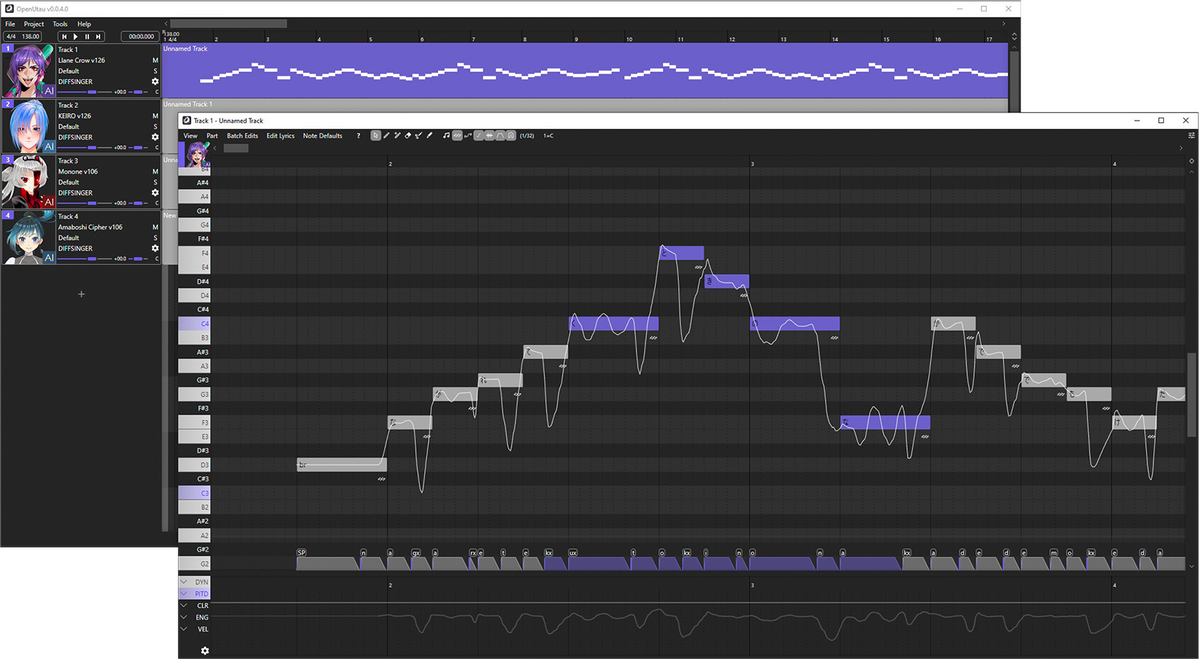
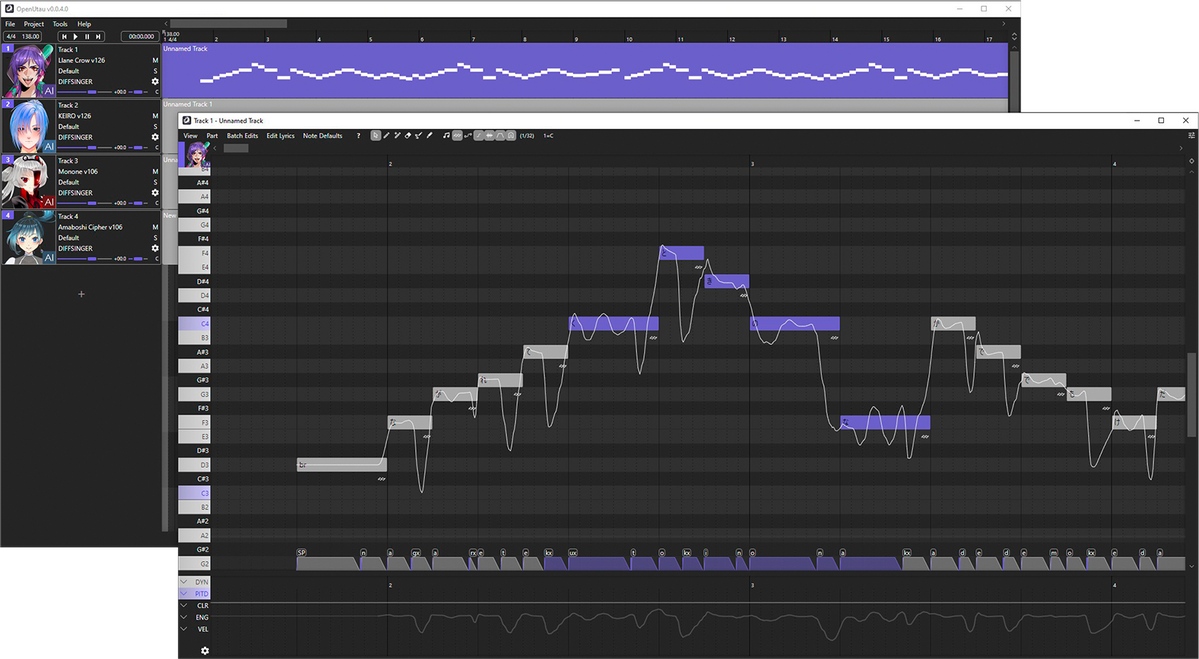
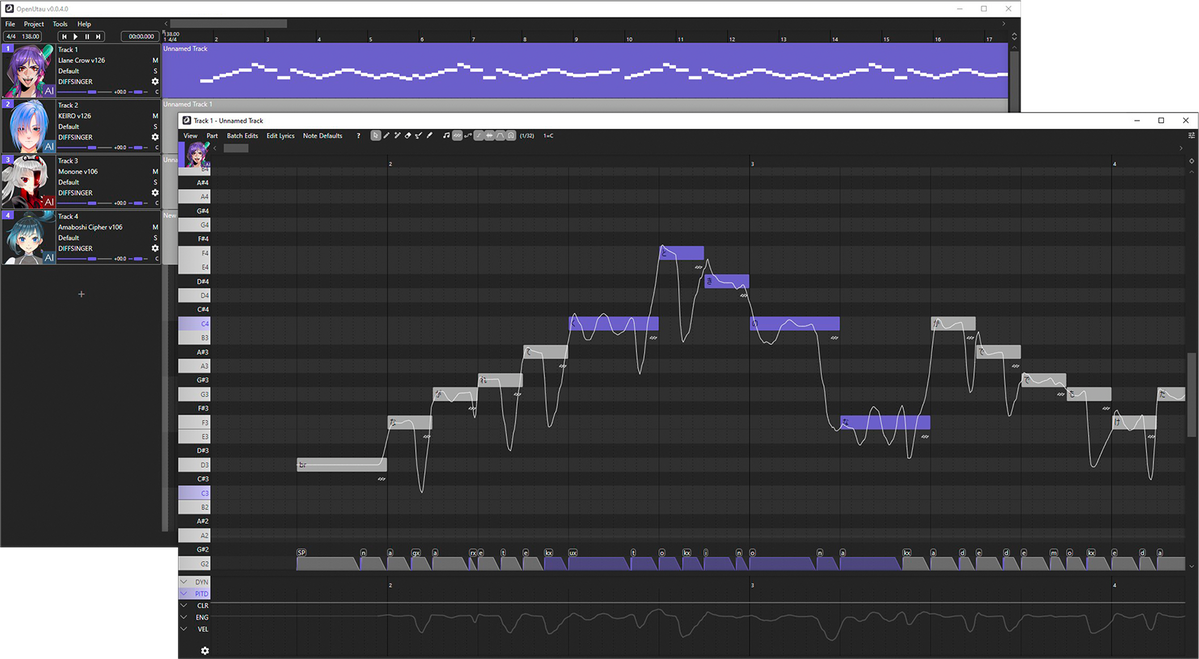
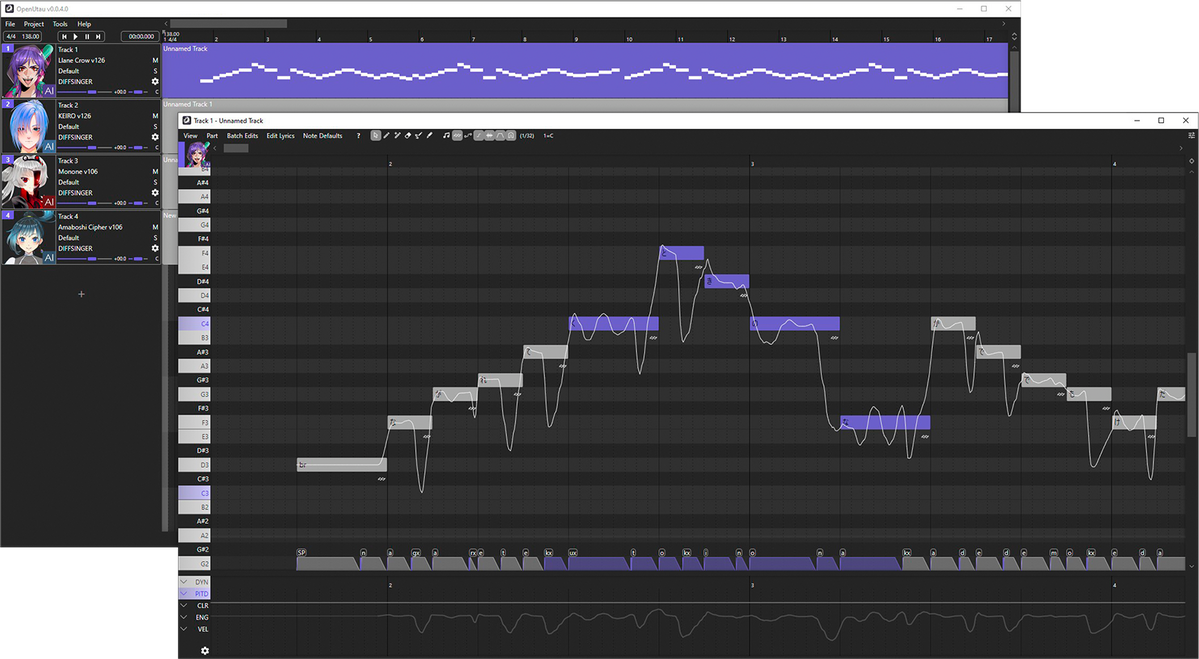
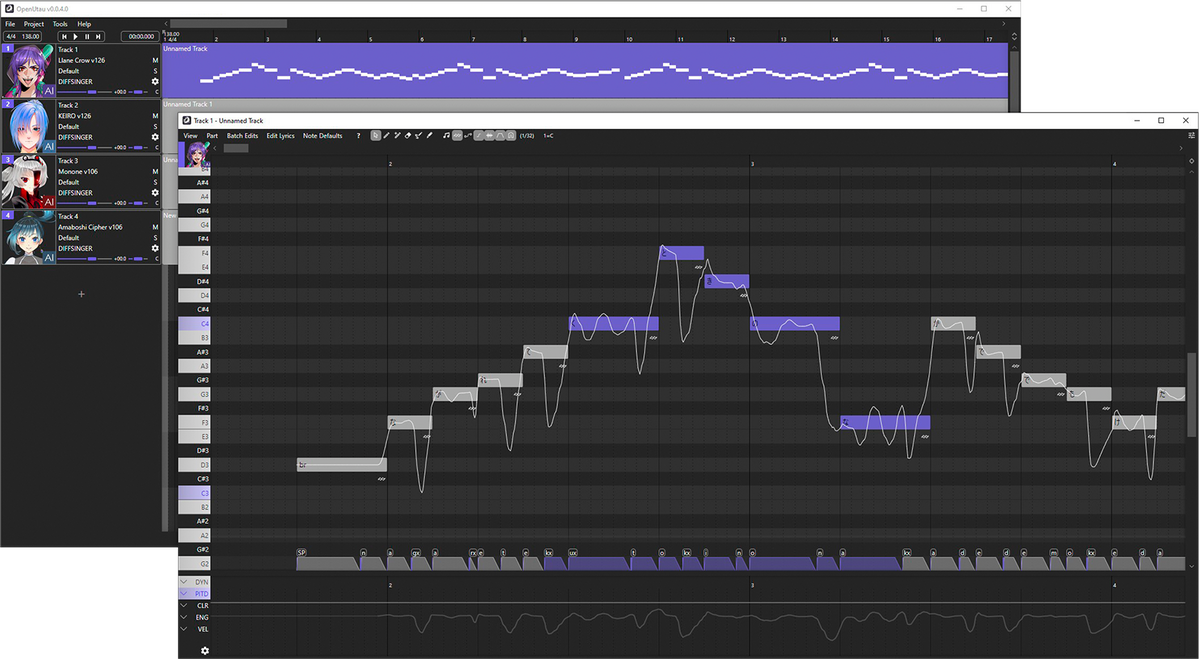
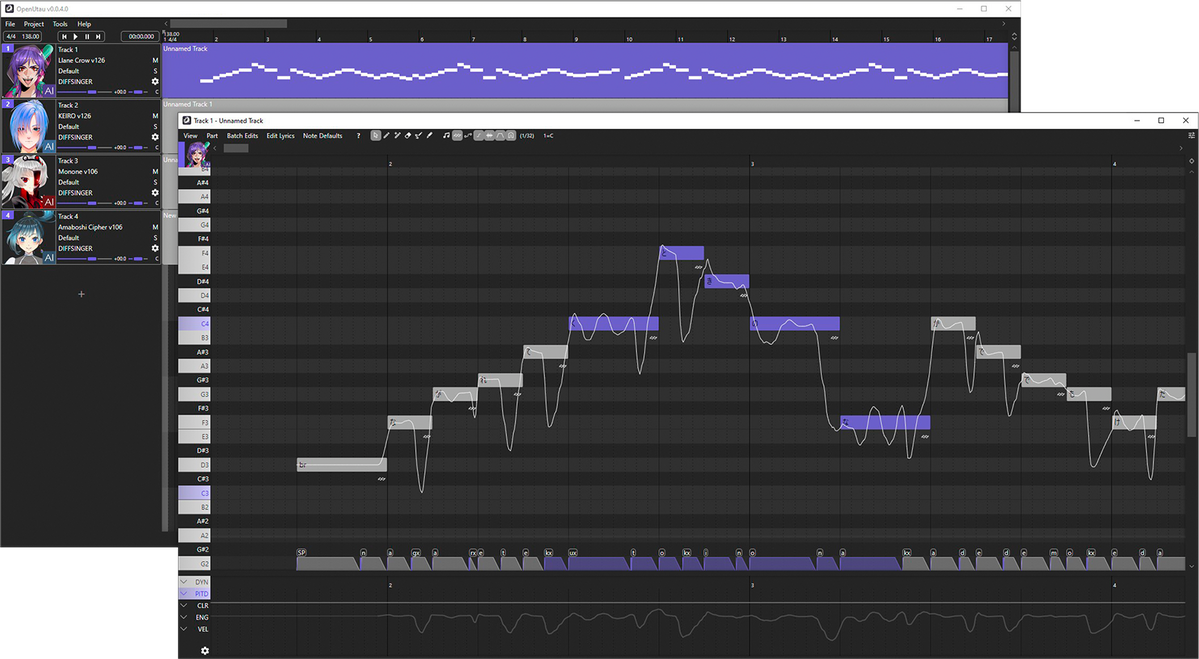
Above is a screenshot of the OpenUTAU musical part editor. This is where the magic happens! You can see a few different things; the control bar at the top, the notes, the phoneme timings and the parameter bar at the bottom. These are the big 4 things you'll be looking at while using DiffSinger.You'll type your lyrics in the notes you see or enter in the part, but what if one part isn't said the way you'd like it to be? You may notice in the screenshot above that some of the lyrics are inside of square brackets "[ ]". Any notes with those brackets will be read as phonemes as opposed to lyrics. You can see how the note with "[f aa]" has the phonemes "f" and "aa" in the phoneme timing section.

If you'd like to load pitch from the built in pitch-tuning model, select the line you'd like to render pitch on and click "Batch Edit > Notes > Load Rendered Pitch
After clicking that, you'll notice that there is a pitch curve drawn on top of the notes you selected!

If you want to make any changes to the pitch, you'll click the "Draw Pitch Tool" at the top (pencil with the line, right of the eraser) or press "4" on your keyboard.

Next, let's play around with the voice modes! To active them in the parameter editor, you'll click the gear icon at the bottom left.

After clicking the gear, select "Add all expressions suggested by renderers" and click "Apply". This will allow you to use all voice modes as curves, but also things like the proper GEN curve, proper VELC curve and pitch expressiveness.
After doing so, you'll be able to select any parameter from the drop down and use it as a curve! You can get some very expressive singing by mixing parameters and voice modes together this way!

Step 5: Conclusion
To conclude, there's a ton of different ways to use DiffSinger, so play around and find out what works best for you! If you have any questions, or run into any issues, please do not hesitate to reach out for me. My contact information can be found below!